经验到底可不可以传递?浅议AI对科研模式的改变|邵晓鹏专栏第三季
笑话一则
2024年10月,有好事者用AI预测诺贝尔物理奖会颁给谁,结果AI不要脸地颁给了自己;第二天,好事者不甘心地用AI再次去预测诺贝尔化学奖会颁给谁,怎知,AI这次更加不要脸,还是颁给了自己!

一、姜还是老的辣!
在学术圈里经常会讨论一个问题“天生资质差的学生到底能不能成为高手”,这个问题其实是一个要命的问题,参与讨论的人就开始掰着指头巴拉巴拉数自己的弟子,哪些人是天生资质差,结果还评上了人才,以此证明天资愚钝者亦可为材!可是,评人才可不是一件小事,有人说它是一项工程,是啊,除了此人学术指标达到“优秀”基本线之外,还有很多其他的因素,难道导师的光环就没照射到评委的眼睛里?显然不是。于是,又有人拿出武侠来说事,典型如郭靖,天资愚钝,学什么都费劲,洪七就经常骂他“笨小子”,可他最终成为了一代大侠。是啊,郭靖虽愚,但不耍小聪明,敢下笨功夫,从这一点来说,他应该还不能算是真正的愚钝。

在工程领域,干了一辈子的老同志往往在经验上超出年轻人一大截,尤其在解决疑难杂症方面,因为“吃的盐多”,变成了“家有一老”,年轻人往往在此方面难以企及,只能靠着“痴长”几年,再去虐更年轻的一代,腔调都变得跟当年的师傅一样,一言一行中都在散发着“姜还是老的辣”的味道。就像很多人在年轻的时候恨自己的母亲——她怎么会是这样,可随着岁月的流逝,她也变成了跟她母亲当年一般一样。
这就有点像热力学第二定律了,熵不断地增加,信息变得越来越少,“今不如古”的腔调一直在影响着几代甚至几十代人,在历史文化领域尤其严重。不信你看看关于尧舜禹的故事细节都会让人惊掉下巴,太细致了!可是,《史记》里关于某一大事件往往却寥寥数笔,这对吗?如果真的是经验不能传递下来,那么,我们现在是不是该找几片树叶系身上、找个山洞住下来、打磨石头去狩猎?

如此悖论,显然不该。但,我们确实看到的现象就是老同志确实经验丰富,解决疑难杂症的本事也确实高人一筹,他们值得我们尊重,值得我们学习。但问题又来了,老同志会不会趋向于保守?答案是肯定的,社会的向前发展就得依靠年轻人“不听话”、敢于突破常规,整个人类历史的发展动力无一例外地都是靠着一代又一代的年轻人的革新在推动。

可是,经验确实是个好东西,吃一堑、长一智,说的其实就是经验。没有它,你现在还是没有记性地一遍又一遍地把手指伸进滚烫的热水中,一遍又一遍地在同一个地方摔倒,也不会有那么多标准和规范,一切都得从头再来。这不得不让我想起数学魔鬼:递归算法,其表示形式简单,效率往往很低,原因就是一切从头再来,不服者写一个斐波那契数列的递归算法试试,算参数值超过47、48的数值时那漫长的等待就会让你开始怀疑计算机的性能,其根本原因就是一切都得从头再来。这也是我当大学老师那几年给本科生讲《数据结构》时经常举的例子,屡试不爽。

在一个单位里,经常会有几个经验丰富的总师和老师傅,他们是这个单位很大的一笔财富,有他们在把关,会少走很多弯路,还能省下一大笔走弯路的学费。因为我们经常会看到一个能人流失之后会导致一个部门、一个方向的衰落,怎么能把这些能人的经验保留下来,减少损失呢?那么,问题又来了,能不能把他们的丰富经验传递给年轻人、甚至是资质愚钝的人呢?
我可以肯定地说:资质差的学生很难成为高手。但到了诺贝尔物理奖和化学奖都同时颁给了AI的时代,让机器智能从零到菜鸟再到高手,让新手变成老司机,这是不是又可以变成可能呢?当然,你可以清醒地看到,机器不存在“资质”差,而且只要给它供电,它就能不知疲倦地一直干下去,比最勤快的人还“勤快”,这能说是资质差吗?如果说资质差,那肯定还是愚蠢的人类在设计时将“愚蠢”植入其中。

那么,在AI时代,如何把经验传递给机器,让机器变成传统行业中的高手高手高高手呢?这其实就是科研模式的改变问题,也就是说,让AI参与到传统的行业中,通过“喂食”一些经典案例,给出输出误差约束,让它变成一个职业高手,不再会因为一个行业高手跳槽而导致工作受挫,甚至它的优秀会让企业变得更强大。比如光学系统设计的问题,近些年来,很多高校的光学工程专业已经不再开设光学系统设计这门课程,导致从业人员少,而随着手机光学摄影之兴起,需求却很旺盛,造成供需不对称;同时,很多有丰富经验的人员还会被一些所谓的大公司高价挖走。在这种情况下,我们唯有改变现有的模式,让AI参与进来,把它训练成老司机,这个时候,你还怕有人跳槽吗?恐怕是有人担心饭碗不保吧?
那下面,我们就从传统的经验传递模式入手,讲一讲AI+光学会有什么样的发展吧。
二、经验与知识
有人说:“知识可以传递,但经验不可以。”这句话的意思其实是指老师能够把书本上人类总结出来的内容传授给学生,但却不能把称之为自身体验的东西让学生身同感受。举个简单的例子,100℃的开水能烫伤手指,这是普遍常识,可以作为知识写进书本教给学生,但烫成什么样,烫的滋味是什么,那得需要学生自己去体会,这种体会就形成了经验。但知识和经验在哲学意义上却存在着不同。

那么,什么是知识,什么又是经验呢?它们到底有什么不同?
我们经常会看到教科书式的知识定义:知识是对某个主题“认知”与“识别”的行为藉以确信的认识,并且这些认识拥有潜在的能力为特定目的而使用。意指透过经验或联想,而能够熟悉进而了解某件事情;这种事实或状态就称为知识,其包括认识或了解某种科学、艺术或技巧。此外,亦指透过研究、调查、观察或经验而获得的一整套知识或一系列信息。

可是,这并不是知识普遍被认可的定义,事实上,知识的确切定义到现在是知识论学者还在争辩的议题之一,柏拉图曾提出古典的知识定义(但他最终没有接受此定义),一个陈述要成为知识,必须符合三个准则:被证实的(justified)、真的(true)和被相信的(believed)(JTB理论)。现今的知识论学者都接受JTB理论的三个准则不是知识的充分条件。但知识的定义到现在都没有统一。

在这里,我们不去咬文嚼字,不去较真,我们暂且还是笼统地把教科书式的内容称之为知识吧,这往往也是狭义的知识概念。于是,我们就可以梳理一下学生在学校的学习过程,就是老师在传授知识的过程。这个过程大多时候其实是纸上谈兵,学的是“死”的知识,要想成为高手,必须要经过大量的实践,从各种成功和失败的实验中总结经验,最终炼成高手。
既然说到经验,我们就来看一下经验的定义。
经验,在哲学上指人们在同客观事物直接接触的过程中通过感觉器官获得的关于客观事物的现象和外部联系的认识。

那么知识和经验的关系是什么呢?
我们查阅资料,得到的结论如下:经验是由人生经历总结而来,实践是认识的来源,而经验只是认识的初级阶段,必须不断深化才能成为人生阅历;知识是人类对物质世界以及精神世界探索的结果总和,及经验的系统固化。经验是个性化的,持久的不断积累;知识是普世化的,理论式的系统总结。人类的知识成果,来自社会实践,其初级形态是经验知识,高级形态是系统科学理论。
对于具备能力的人来说,经验更重要,当然,经验是能力的另一种形式;对于不具备能力的人来说,知识更重要,因为学习知识是形成能力的载体。

对于处理新问题复杂问题的情况,知识和经验都重要:对于一个恪守自身处事原则的人来说,经验比知识更重要;对于一个不断突破提高自身能力的人来说,知识更重要。对于一个具有较高智慧的人来说,其会平衡知识增长和经验积累的关系,使得知识与经验形成互动,知识和经验的重要性一样。生活中,我们看看周围的人,基本上都可以对号入座。
关于哲学上的事情,我们不关心,我们关心的是怎么能把老师傅的经验保留下来,不再发生因为某个人的离开而导致技艺失传的事情,也不要再发生一群不肖子孙集体出来做“违反祖宗决定”的案例!
需要说明的是,我们在这里简单粗暴地把课本上的内容称之为知识、把长期实践中摸索出来的诀窍称之为经验吧。经验往往是非线性的,尤其是更高层次上的行为,它往往是建立在厚实的知识基础上的。
三、九斤老太的魔咒—知识的传递模式
门徒制是中国古老的师徒传艺模式,它普遍存在于民间,从泥瓦匠、木匠到书法、绘画,从工艺到艺术,贯穿整个人类历史。但我们经常听到一个词:“失传”,为何会失传?在各种史书和文学作品中,也经常会讲述一种工艺、技术失传,比如诸葛亮的“木牛流马”、张衡的地震仪,也经常会看到一个帮派从兴到衰,比如全真派的王重阳,教出的七个不争气的弟子加起来还不如他一个,典型如鲁迅笔下的九斤老太所言:一辈不如一辈了!
即使在现在,学术界也流传着一句话:弟子很难超过导师,除非他换一个与导师不同的研究方向。当然,前提是这个导师必须很牛,因为我们经常会看到弟子超过导师的例子;也有人是什么方向火他就换什么方向,早就把祖宗八辈给忘得一干二净,也没见他真正成为行业的大牛,为什么?再看看现在的书法界,狮吼、射墨、身体为笔等各种行为艺术大师涌现,也会看到全篇涂鸦之草书,污染了我们的眼!

为什么会一辈不如一辈呢?我们来看看老师传授知识的过程,其实就是知识传递的过程,也是一个信息减少的熵增过程;其中老师掌握知识的水平、讲授方法和学生的理解能力,都是导致熵增的原因。在大学里,很多“能力超强”的老师什么课都敢讲,只要你敢听,一份“皱巴巴”的陈年老PPT照着读几年,照样混日子,其知识传授能力可想而知。当然,学生是否认真学又是另外一个问题。按照这种说法,九斤老太的魔咒确实难破。

可是,大学里却不乏优秀的学生,他们的脱颖而出实际上是他们具有很强的思考能力和自学能力,善于借助于外部资源提高自己,从而破掉了九斤老太的魔咒。这当然不违反热力学第二定律,因为系统是开放的。破解“弟子不如师”的魔咒要靠自强,也就是说导师是引路人,教的更多的是学习方法,而不仅仅是具体内容;知识不断更新,需要强大的自学能力,才能有新的知识补充。
接下来,我们用数学模型来阐释一下“弟子不如师”的原理。需要说明的是,知识教授传递的过程通常被认为是线性的。
知识的传递大体可以画出下面图示的形式,师傅传授的知识(三角形标注)通过弟子的眼、耳等传感器,经过他们的大脑(思维处理器),实际学生学习到的知识就可以写成G知识=G1·G2的形式。显然,师傅传授的知识到了学生那里会损失,其损失程度决定于学生的传感器和处理器性能。这也就解释了同一个老师教出来的学生成绩不同的原因,眼睛看没看见、耳朵听没听见,有没有入脑,脑子好使不好使,努不努力,都会导致成绩各不同。注意,这个阶段还仅仅是纸上谈兵的阶段。

学习完了,还要有行为输出,也就是实践阶段。一个人的行为输出还要受到执行机构G3的限制,执行机构主要取决于其自身综合素质,具体包括观念、人为技巧、业务、身心等等,于是,行为的输出可以写成如下形式。这就能解释为什么有的人眼高手低,赵括同学用他个人的表率硬生生让后人嘲笑了2000多年;你也会看到有的人老师怎么教,他的动作都做不出来,没办法,天生素质所限。当然,同学聚会的时候你也会发现当年风风光光学习前几名的家伙大多混得没有你们预期的好,主要原因就是出在G3这一块。

我们也可以把这个过程统一简化为传递函数来描述,它的表示形式就更简单一些。

以上这些都是关于知识传递的论述,整个就是一个线性的传递过程,成功的解释了九斤老太关于“一辈不如一辈”的现象。
那么经验能不能传递呢?
四、老司机的成长之路
一般的说法是经验不能传递,只有在经验转换为知识后才能传递。

为了说明这个问题,我来举个做菜的例子。我们吃中餐时,经常会打听哪个餐馆做的菜好吃,而从来没有发生过边家村的肯德基做得比徐家庄的肯德基好吃这样的事儿,原因就是中餐没有标准化,大厨拥有的更多的是经验,于是经常会出现盐少许、水适量等模棱两可的描述。如果中餐标准化,它就变成了跟肯德基一个德性了,不信你到美国去试试,加州做的中餐跟德州的基本上是一个味,当然,这还没有完全标准化。没有标准化,就给了一群老江湖开辟了一片广阔的市场,看看那些喝不起的茶叶的价格,再看看所谓关于雪水冰藏冲茶等的各种讲究,捂紧你的钱袋子赶紧跑——他们在征智商税!
言归正传,我们继续讨论AI的问题。自深度学习发布以来,往往会看到一种AI过处,片草不生的场景,先是AlphaGo在围棋方面战胜了人类围棋高手,然后是Alphafold“瞬间”解译了全球那么多蛋白,一夜间让很多人失业,接着就是AI进入到了自动驾驶领域。

据说,这个世界上电动车只有两种,一种是Tesla,另外一种是别的品牌;而能称得起老司机的却只有Tesla,不管号称遥遥领先ADS 3.0者的嘴有多硬,都闭口不敢提L3级别,最多学隔壁叫个L2.985,因为现在吹牛要上税了——新规定明确说明:凡L3级别自动驾驶车辆发生事故,车企负全责。再看这个Tesla,硬是从小白被一个叫埃隆·马斯克的、满脑子与传统格格不入的疯子训练成了老司机,而且其进化速度非常快,以至于遇到紧急问题时会迅速做出类似避开人而撞墙的决定,让你怀疑它是不是道德模范。

AI之所以能从0经验到老司机,究其原因是它本身做的是归纳,也就是会总结经验,然后通过神经网络能把经验变成AI自身能理解的知识,不断强化自己,使得能力超强。它还有的特点是可解释性差,言外之意是它怎么学的,人类搞不懂,但它确实随着喂食的数据增加,能力越来越强;而且,它能把不同来源的数据也都能吃得下,相当于把各种题都遍历着做了一遍,而且不会遗忘,于是本领就越来越强。


图 AI神经网络可视化
到目前为止,Tesla已经收集了超过4亿公里的驾驶数据用于FSD系统的训练,这些数据对于提高自动驾驶系统的安全性和可靠性至关重要。可以想象,任何一个人不可能有驾驶4亿公里的丰富经验,而且各种路况都有可能遇到,这样的老手恐怕是前所未有了!据说,现在开启了Autopilot自动辅助驾驶功能的Tesla车辆,平均行驶约1139万公里只会发生1起交通事故。

图 自动辅助驾驶
五、科研范式上的创新
爱因斯坦曾经说过:“如果一个想法在最初并不荒谬,那它就没希望!”

2014年埃隆·马斯克就有个想法:造一辆这样的车,身处美国的一端可以召唤处于美国另一端的车,它能自动开到自己跟前,而无论距离有多远。当时,这只能称之为“奇思妙想”,而现在它已经变成了现实,其幕后的主角其实是AI。
同样的事情也发生在了2024年诺贝尔化学奖的主角AlphaFold上,从诞生到获得诺贝尔奖仅仅只有4年时间。DNA储存着我们的遗传信息,然而,纷繁复杂的生命活动是由大量的不同种类的蛋白质来完成。20种氨基酸经过不同长度及排列组合,构成了生命中数量庞大的蛋白质种类。要发挥生物学功能,蛋白质需要正确折叠为一个特定构型。每个蛋白质的氨基酸链扭曲、折叠、缠绕成复杂的结构,因此,“看清”它们的结构对理解其功能至关重要,但这通常需要花很长的时间,有些甚至难以完成。

图 蛋白质折叠过程
蛋白质结构过去通过诸如X射线晶体学、低温电子显微镜和核磁共振等技术进行实验确定,这些技术既昂贵又耗时。过去60年努力只确定了约170,000种蛋白质结构,而所有生命形式中已知蛋白质超过2亿种。同时,人们还尝试用许多计算方法来解决蛋白质结构预测问题,但除了小而简单的蛋白质外,它们准确性还远远远没有接近实验技术,蛋白质结构预测比赛CASP于1994年发起,然而,直到2016年,对于复杂结构预测的最好结果也只能达到100满分的40分。
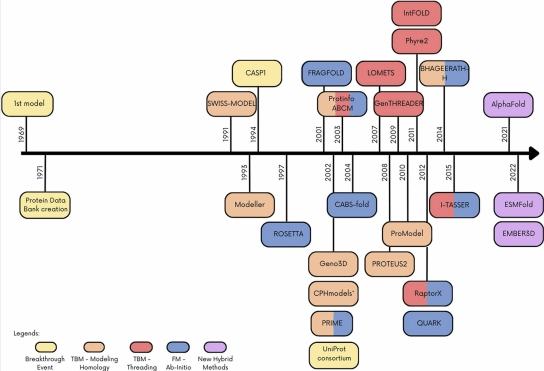
图 蛋白质结构预测发展历程
2020年,Google DeepMind推出了基于AI的蛋白质结构预测工具AlphaFold 2,在CASP比赛以92.4分登顶第一。它通过独特的神经网络和训练过程设计,第一次端到端地学习蛋白质结构。整个算法框架通过协同学习蛋白质的多序列比对(MSA)和氨基酸对(pairwise)的表征,将蛋白质序列的进化信息、蛋白质结构的物理和几何约束信息结合到深度学习网络中,能够根据氨基酸序列来准确预测蛋白质的三维结构,但其对蛋白质复合物结构预测的效果不佳。
2021年10月,DeepMind团队进一步推出了AlphaFold-Multimer,用于预测蛋白质-蛋白质复合物的结构和相互作用,不过,扩大单一深度学习模型能预测的复合物范围一直很难,因为不同类型的特异性相互作用差异太大。
2024年5月8日,DeepMind 发布了新一代AlphaFold3。它能够预测含有蛋白质数据库(Protein Data Bank)内几乎所有分子类型的复合物的结构,包括配体(小分子)、蛋白质、核酸(DNA和RNA)如何聚集在一起并相互作用,以及预测翻译后修饰和离子对这些分子系统的结构影响。其核心是一个对AlphaFold2中蛋白质语言模型Evoformer进行改进, 并使用扩散网络进行预测,扩散过程从一团原子云开始,经过许多迭代优化,最终生成最准确的分子结构。

图 基于扩散网络的AlphaFold3框架
回想从前,在AlphaFold出现之前,往往需要耗费整个博士生阶段,并花费数十万美元,才能解析一个蛋白质的精确三维结构。AlphaFold仅仅用了不到3年时间就已经成功预测了数亿个蛋白质结构,几乎覆盖了地球上所有已知的蛋白质,以当前的结构生物学实验进度,完成这一工作量可能需要耗费十亿年时间的呀。
在我写了《深度学习:你行不行?》一文后,很多人觉得我对AI持否定排斥的态度,我只能说“Too young,too simple,sometime naive”了,他肯定也没有读懂我的文章。在深度学习兴起之时,取巧者多在信号处理方面写了大量的文章,却止步于与物理的深度结合,取法乎外者也。
在光学领域,逐渐地,有很多人尝试将AI作为强大的工具挖掘新能力,发展新质生产力了。一个典型的想法就是能不能让AI去设计光学镜头,你看看,大学里不愿意教,学生不愿意学,单位里紧缺,越来越吃香,甚至流失了会造成重大损失,而这样的活儿,能不能交给AI来做?
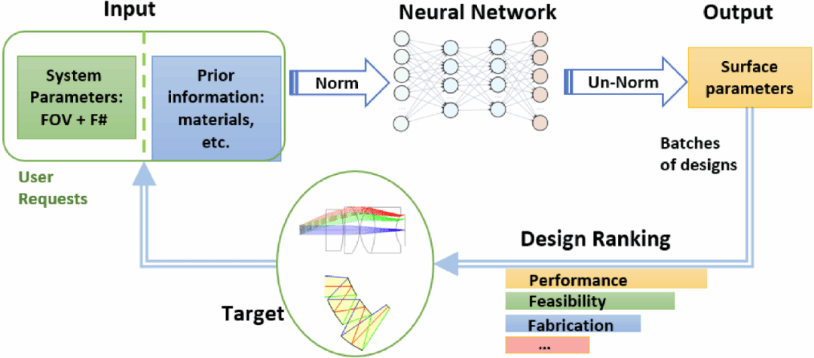
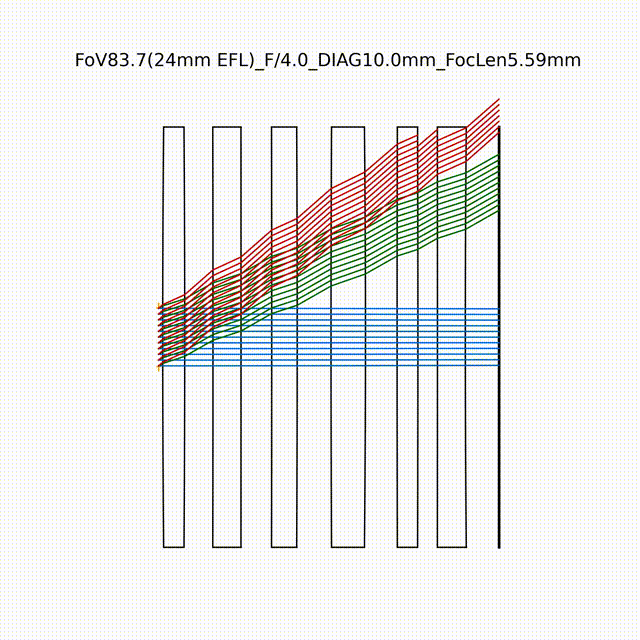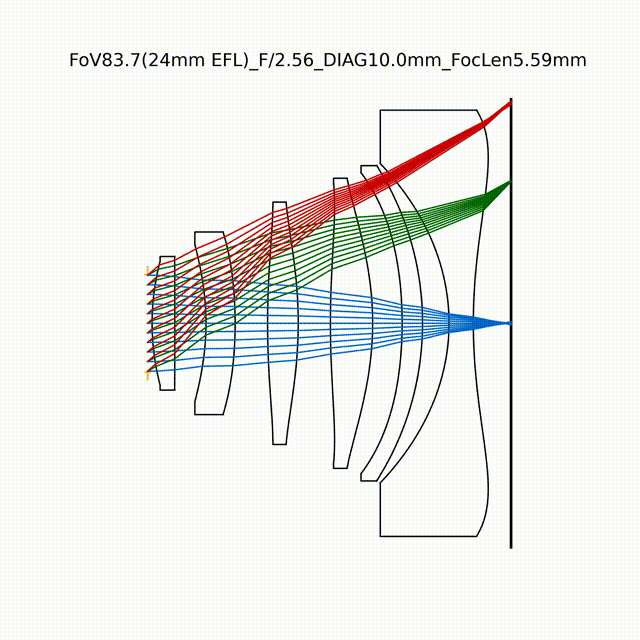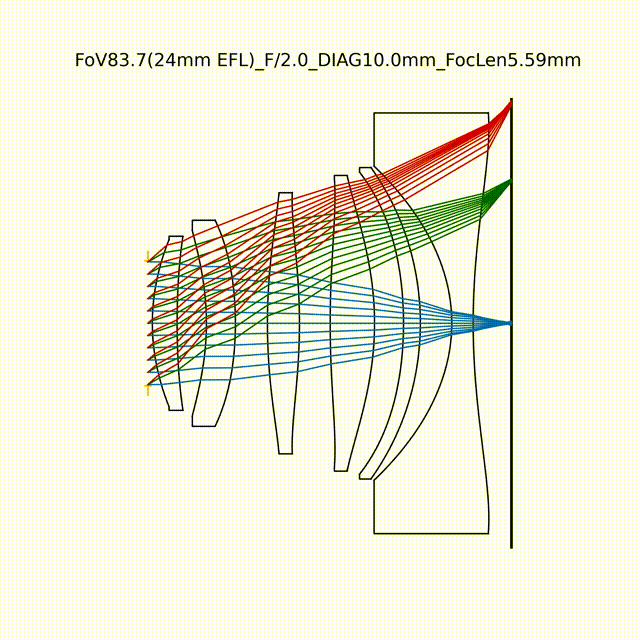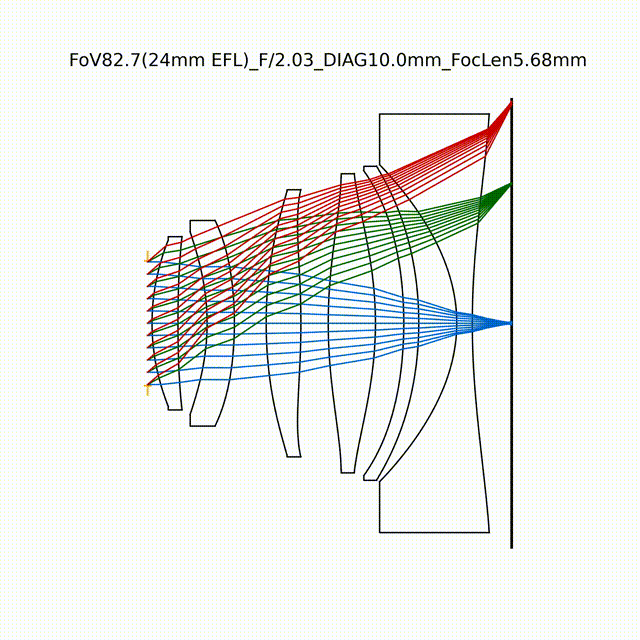
在光学设计中,光学元件的参数优化函数通常是非凸的,因此在系统优化过程中容易陷入局部最小值。传统的光学系统设计方法常依赖于对基础结构的微调,需要持续的手动监督,显然很不适合光学与算法的联合设计。2024年7月,阿卜杜拉国王科技大学的Wolfgang Heidrich等人提出了一种基于课程学习的光学参数自动优化方法(Curriculum learning for ab initio deep learned refractive optics),不直接寻找最终设计方案,而是将整个设计过程分为几个小阶段,每个阶段针对特定问题,逐步增加任务的难度,通过分步骤完成成像任务,最终实现全视场的高质量成像。基于课程学习的DeepLens优化过程采用可微光线追踪进行成像模拟,并通过反向传播完成系统参数优化。通过放松畸变控制,增强其他像差的控制,以实现系统视场的扩展优化。同时,引入光学正则化,避免在优化过程中出现不符合实际或难以生产的自交和激进非球面等异常结构。

如图所示,在几乎平面且随机初始化的镜头几何结构基础上,采用课程学习的方法,逐步增加孔径和视场的优化任务,最终设计了具有80.8°视场、F/2.0光圈的高质量光学镜头。

在化学领域,AlphaFold是作为一个具体的案例成为了2024年度的诺奖主角,但在物理领域,AI获诺奖却是作为一个通用的工具而出现,并没有给出具体的案例。这其实在告诉我们,AI与物理的结合空间很大,即便与光学的结合也有太多的事情值得去开发。
人工智能经历了从监督到半监督再到无监督,到了自主学习的进化阶段,它的发展突飞猛进;当然也会面临一些问题,比如大数据、模型设计和进化算法等,但这些对敢于挑战自我的人来讲都不是问题。在科研范式的路上,AI该怎么设计,如何更大化地发挥AI的功能,留给我们更多的其实是深度思考。

图 AI发展趋势
六、救赎
没有人能救你,能救你的只有你自己!同样的,我挑战不了别人,只能挑战自己。


 当前位置:
当前位置:
